앞서 logstash 를 이용해 source data를 가공하여 ES에 저장하였다.
데이터를 ES에 저장한 뒤에는 꼭 index를 생성해주어야 하는데 logstash가 데이터를 ES 에 저장하는 순간 ES 상에는 index 가 생성되고 mapping 까지 완료된 상태이다.
그러나 kibana 를 통해 접속해보면 index가 나와있지 않는데 kibana가 관리하는 index를 ES로 부터 불러와야 한다.
kibana 에 접속하여 왼쪽 메뉴에서 Management 를 누르고 kibana 항목의 index patterns 를 클릭한다.
그리고 + Create Index Pattern 을 선택하여 logstash 에서 사용한 index 명을 입력해주고 “Next step” 을 클릭한다음 Time Filter를 @Timestamp 를 선택하여 index를 생성해준다.
이제 kibana를 이용해 저장된 데이터를 분석하고 시각화를 해보도록 한다.
ES에 저장된 데이터중 하나의 document를 살펴보자
1 | { |
_source 하위에 있는 field는 원본 데이터인 csv 파일에 logstash 파 추가로 생성한 field 정보가 붙여져 있다. 그리고 logstash 에서 filter plugin 으로 수정한 필드는 fields 하위 영역에 포함되어 있다.
이제 위 데이터를 가지고 출퇴근 소요 시간을 계산하려고 한다.
간단히 생각해서 하차시간 - 승차 시간 = 통근 소요시간 이라는 공식이 생각나는데 아예 통근 소요시간 필드를 하나 추가해 주면 여러므로 이용할때가 많을거라 생각이 들었다.
구글을 열심히 검색해본 결과 index에 새로운 field를 생성하는 방법이 나와 있었는데 Management 를 누르고 kibana 항목의 index patterns 를 클릭하면 총 3개의 탭이 나온다. Fields, Scripted fields, Source filters 가 있는데 이중 Scripted fields 를 클릭하고 Add scripted field 를 해준다.
painless 라는 문법을 가지고 새로운 field 데이터를 생성하는 방법이 있는데 하차시간 - 승차 시간 을 계산한 값을 새로운 필드로 생성하고자 한다.
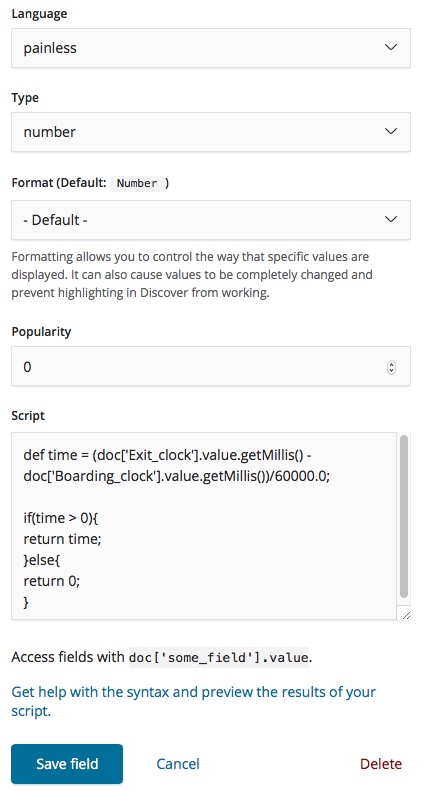
통근 시간계산하는 스크립트는 다음과 같다. Boarding_clock, Exit_clock 는 date type 이므로 millisecond 로 데이터 형태를 변형 할 수 있고 이를 1시간을 분으로 표현한 60으로 나누어 주면 통근 소요시간이 분단위로 계산되어진다.
원본데이터중 쓰레기 값이 있는 경우가 있기때문에 음수값이 나오는 경우는 0을 리턴하도록 하였다.
1 | def time = (doc['Exit_clock'].value.getMillis() - doc['Boarding_clock'].value.getMillis())/60000.0; |
필드를 추가한 김에 몇가지 정보를 더 추가해 보자.
원본데이터를 보면 승차역,하차역이 따로 되어있어 하나로 합쳐진 필드명이 있으면 좋을것 같다.
간단히 두개의 필드명을 합쳐주면 된다.
1 | doc['Boarding_Station.keyword'].value + '-' + doc['Exit_Station.keyword'].value |
그리고 계산한 통근 시간이 출근인지 퇴근인지 표시해주는 필드도 필요하다. 이경우는 조금 복잡하였는데 기본적으로 ES는 timezone 이 UTC 로 기본 셋팅되어 있어 timezone을 변경하지 않으면 시간이 꼬여서 계산하기 힘들어진다.
timezone은 Asia/Seoul 로 바꿔주고 승차시간이 13시 이전이면 출근으로 간주하는 스크립트를 만들어 줬다.
1 | def commuteType = LocalDateTime.ofInstant(Instant.ofEpochMilli(doc['Boarding_clock'].value.millis),ZoneId.of('Asia/Seoul')).getHour(); |
이로써 시각화에 필요한 데이터를 만드는데 얼추 끝난것 같다.
다음 글에서는 Kibana 에서 제공하는 시각화 도구를 이용하여 통근시간에 대한 다양한 분석을 시도 해보도록 하겠다.